
This is the second entry of the ECS Scaling blog that covers how to properly scale the EC2 cluster of instances that are running your ECS Tasks. When I wrote the first entry, ECS Auto Scaling, I discussed how to scale the actual ECS tasks (a.k.a. Containers). Then, shortly after, AWS went and announced the AWS Fargate service, which essentially handles the scaling of the actual instances with ECS in a simple manner. Now it’s been close to two years since that entry I wrote, and I will be honest: I did not write the second entry on EC2 scaling because Fargate seemed to nullify it at the time.
However, over the past two years I have worked with numerous clients who need to run their own EC2 cluster for a variety of reasons. Regardless of the reasons, the ability to run your own cluster of EC2 instances with ECS is still a viable solution, and this blog entry is now here to complete the original idea of showing you how to scale your instance cluster.
Picking up where I left off in the previous blog entry (please read it if you need a refresher on this topic), we have a fully functional Application Auto-Scaling solution in place for the ECS Service. In our example we have the following ECS configuration:
ECS Cluster Name: Sample WebApp
EC2 AutoScaling Group: ‘sample-webapp-ec2-cluster’
ECS Service Name: ‘sample-webapp-ecs-service’
CloudWatch Alarm Name: ‘Sample-WebApp-ECS-Service-High-CPU’
CloudWatch Alarm Name: ‘Sample-WebApp-ECS-Service-Normal-CPU’
We were scaling the ECS Tasks based on the ECS Service CPUUtilization metric. If the metric was above 80% for 5 consecutive periods, the ECS Service would add 1 container to the service. If the metric was below 35% for 10 consecutive periods, we would set the number of desired tasks in the service to 1.
To review the point of this exercise, remember that we are doing a 1-to-1 mapping of containers to instances for ease of use. Right now, our environment is set up so that the ASG (AutoScaling Group) has 1 instance running, and 1 task on that instance.
While we have configured the container scaling, we have not adequately ensured that when we add containers from this service into the cluster there is enough capacity to actually run these extra containers. Adding actual cluster capacity is the job of EC2 scaling.
The EC2 scaling policies should be based on whether we want to add or remove capacity only when needed. We could easily set up the cluster to have extra capacity available at all times by simply increasing the desired capacity of the ASG to n+1 tasks at all times. The instance would just go unused, but you could have it readily available. However, in a tight budget we want to run an instance only if we have to run the instance.
In order to configure this to work with our ECS Cluster, we configure the EC2 AutoScaling Group to scale on the same CloudWatch alarms that our ECS Service is using. This will allow the ASG to add/remove instances at the same time that containers are being added/removed. In the case of our example, if the ECS Service scales up to add 1 container, our EC2 Auto Scaling Group will scale up by 1 instance as well. Once the instance is up, the ECS service will see the extra capacity and start the task on the server.
As with the ECS Service scaling, we need to provide a Scale-Up policy and Scale-Down policy for the EC2 ASG associated with the ECS Service.
Setting up the Scale-Up ASG policy
First, in the AWS console, navigate to EC2→AutoScaling. Select the group named ‘sample-webapp-ec2-cluster’. Click on the tab named ‘Scaling Policies’. I am going to be using Step-Scaling to add instances. Step-Scaling allows us to add instances based on the range of the value of the metric without needing to wait for the previous scaling action to complete. In the resulting window shown by the tab, click ‘Create a scaling policy with steps.’
Name your scaling policy ‘Scale-ECS-Cluster-Up’. In the ‘Execute Policy when’ drop-down, select the Alarm named ‘Sample-WebApp-ECS-Service-High-CPU’. In the ‘Take the Action’ area, enter ‘1’ for the number of instances to add. A screenshot of this setup is below:
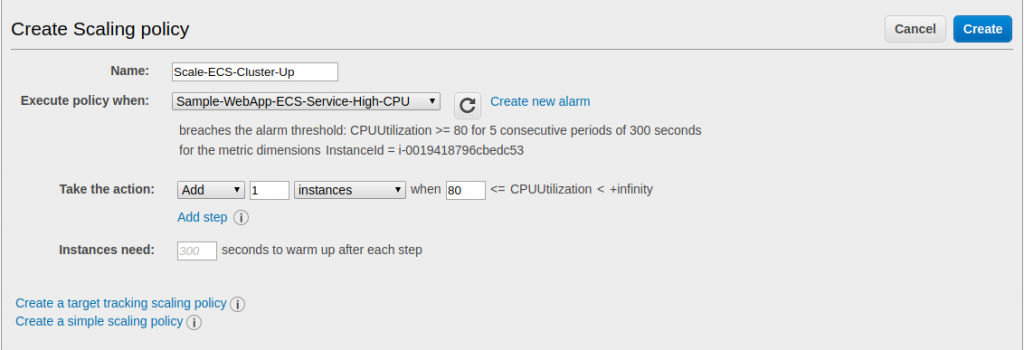
With Step-Scaling, we are telling EC2 to add 1 instance if the Alarm has a value of 80 or higher. You could add additional steps with step-scaling by click ‘Add-step’. If you do this, you would be presented with another line for an action. This is where you could configure the first action to add 1 instance if the metric value is between 80 and 90. Then for the second action, you could add, say, 2 instances if the value was between 90 and above. We will not do this in this exercise, but I mention it now as it is a very handy thing to do to allow you to scale up faster under extreme loads.
Click ‘Create’ and your first EC2 scaling policy will go into effect.
Setting up the Scale-Down ASG policy
Next, we need to have a policy to scale down the number of instances. This process is the reverse of the Scale-Up policy. However, instead of gradually removing instances we will just set the desired capacity to a fixed number of ‘1’. Remember, if our ‘Normal’ alarm is triggered, we know that we can run at our base configuration of 1 server and 1 task. There is no need to try and remove 1 instance at a time since the ELB service will drain connections properly and not “cut-off” existing requests.
Follow the same process of adding a policy in the ASG, but provide a different name such as ‘Scale-ECS-Cluster-Down’. The difference in the action step is to select the option of ‘Set to’ and provide a value of 1. Leave all other values as they are shown below:
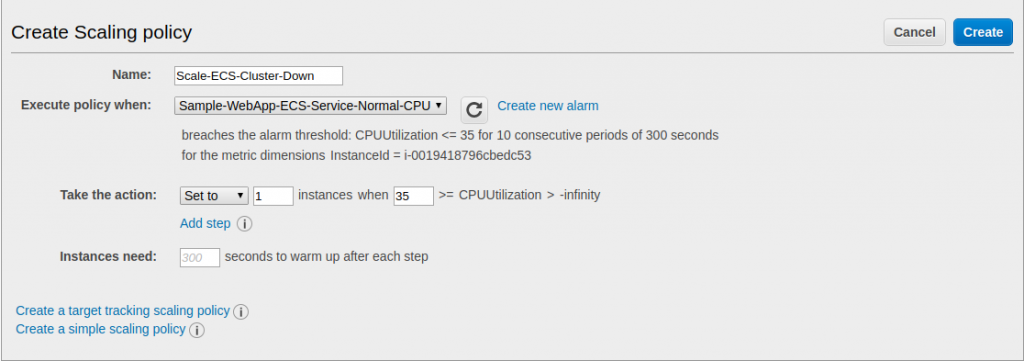
Click ‘Create’ to put the policy into effect.
What is now configured is a scale-up and scale-down policy for your ECS Cluster. It will add an instance when your ECS Service scales to add 1 container to the service. This will provide the On-Demand capacity required to run the additional container. Once normal load is seen, the ECS Service would remove a task from the service and this alarm would also remove an EC2 instance from the cluster.
In the case of this exercise, once the instance is registered with the ECS Cluster, the ECS Service Auto Scaling will now be allowed to start the extra container in the Service, and it does so automatically. The Service will continue to run at these levels until its scale-down policy activates, at which time it will lower the tasks desired in the service to 1. This, in turn, will also trigger the Scale-Down policy of the ASG associated with the service. Note that the EC2 scale down is independent of the ECS service scaling. They are intertwined in this example, but they are separate actions. This is important to realize because as you become more comfortable with the scaling of ECS and EC2, you technically could scale the EC2 cluster on its own metrics.
For example, if we had multiple ECS services running in the cluster, we would not want to scale the cluster up and down based on one ECS Service metric. We would want to have a metric that perhaps watches the ECS Cluster CPU% as a whole, and scales up and down on that number instead of the ECS Service metric. This can become complex, and you need to ensure that you do not inadvertently remove an instance if it is needed by other ECS services, but it is definitely possible to do this as well. It just takes a little more practice and testing to accomplish using the same principles.
Final Thoughts:
At this point, you have a fully functional ECS Service that can scale up and down based on load. In our example, we added a task to the ECS service if we experience a high CPU% metric on the service itself. This metric is also used as the AutoScaling Group’s source for scaling up the number of instances in the ECS Cluster.
A few things to note when considering your scaling policies in an ECS cluster:
1.) Most users I work with start with a 1-to-1 mapping of Clusters to Services. This is great for understanding the relationship between the two with scaling, but eventually you will want to run more ECS Services on one cluster to save costs. This is the point where it is important to know exactly how many CPU units and memory your container needs, as it will affect your scaling policies and alarm thresholds.
2.) There are more than a few ways to handle the scaling. If it’s more important to you to ensure that you have extra capacity readily available in your ECS cluster so that you do not need to wait for an instance to launch, always have n+1 instances in the Desired Capacity value of the ASG compared to the number of tasks you would be running. For example, if you have 2 tasks that are running, you would have 3 instances in the cluster. As you add 1 task, you add 1 instance so that one is always ready.
3.) While this exercise shows a basic scaling setup for ECS and EC2, you’ll notice that I was triggering a scale down alarm really quickly. In practice, I usually set the Normal Alarms to trigger after a longer period of time (e.g. 1 hour) so that I can be assured that traffic is not spiking up and down, thus causing the scaling to add an instance, and then remove it 10 minutes later. Try to scale down only after a consistently longer period of time is observed at ‘normal’ levels.
4.) Scaling properly takes practice. Don’t be afraid to try different policies and alarms. In fact, I would encourage you to try all types of metrics and policies to see what fits your needs best. Remember, you can always trigger an alarm by sending a value to CloudWatch manually to trigger the scaling actions.
That concludes this blog series on ECS scaling. In AWS, things change daily, so it is quite possible that in one month there may be another way to scale a cluster for an ECS service, but the principles always remain. You want to scale your containers based on a defined metric, and add/remove instances based on a metric that provides the EC2 AutoScaling Group with the proper metric that dictates if auto-scaling should add or remove instances.
Good luck!
Useful Reading:
- AWS ECS Auto Scaling (Part 1)
- AWS ECS Auto Scaling (Part 2)

