

In the last few years, the capabilities to analyze data and do amazing things with it have grown exponentially. For decades, the education sector has been storing usage data in Learning Management Systems (LMS), Student Information Systems (SIS), and on other multiple systems. Multiple organizations want to use that information now, and when doing it, are finding multiple obstacles in the way.
One of those problems is simply the movement of information from one place to another, extracting the data from the LMS or SIS, and placing it in the right location so the analytics tools can consume it.
Another problem is transforming the data in the format the analytics tool requires.
Those two issues have multiple solutions, and a lot of possible technologies can help with these ETL (Extract, Transform, Load) processes.
But a third problem, which does not have a simple solution, is how to relate information from the different systems so that the analysis can use the data in a global way, interrelated, and not separately. Explained with an example:
What if the institution wants to research whether or not there are any differences in the number of posts in the LMS forums, based on the student’s state of origin? Do people from Oregon post more than people from Alaska? Well, surely this is not a very interesting thing to discover, but the real question is… if the students’ states are in the SIS data, and the number of posts is in the LMS data… how do we link all that information, one to the other, so that we can generate queries like this one?
This issue has some answers too, of course, but not as trivial as the basic ETL ones. One of the possible answers for these types of needs is to use a system called the Unizin Data Platform, or UDP.
On a recent project, we were asked to extract, nightly, all the data from a D2L Brightspace LMS and transform it in a way that could be ingested in a UDP system, which was receiving the data from the SIS system as well as real-time events with Caliper format. In this article, we will present the solution we designed for this task.
BUT FIRST, LET’S LEARN A LITTLE MORE ABOUT UNIZIN UDP
As said before, one of the big benefits of using a system as UDP is the fact that the data can come from different places and will be joined internally, so it can be queried as a whole.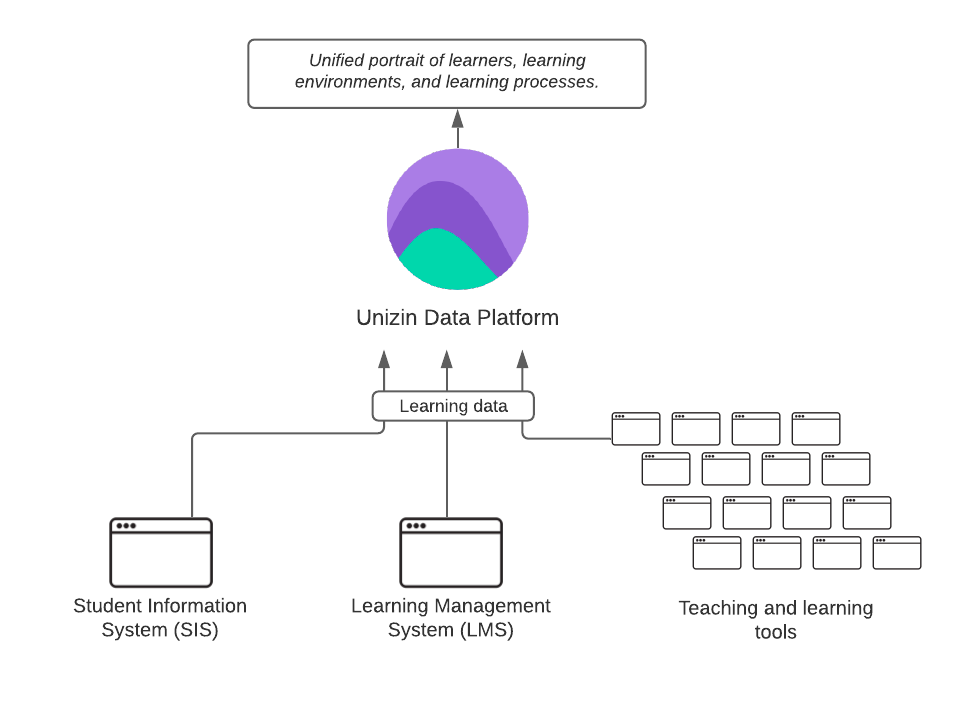
Fig 1: Source: https://resources.unizin.org/display/UDP/Platform+overview
UDP stores two types of data:
- Context data: This is the data that defines things like the courses, the terms, the credits, the departments - everything that explains the context around the user actions. If a student sends a submission for an assignment, then the assignment, the course of the assignment, the program, the school, etc. are the “context data,” as all these things are needed to understand the submission.
- Behavior data: This is related to the user actions. In this case, the fact of the student sending a submission is the behavior data. We could say that the “events” happening in our system are the behavior data.
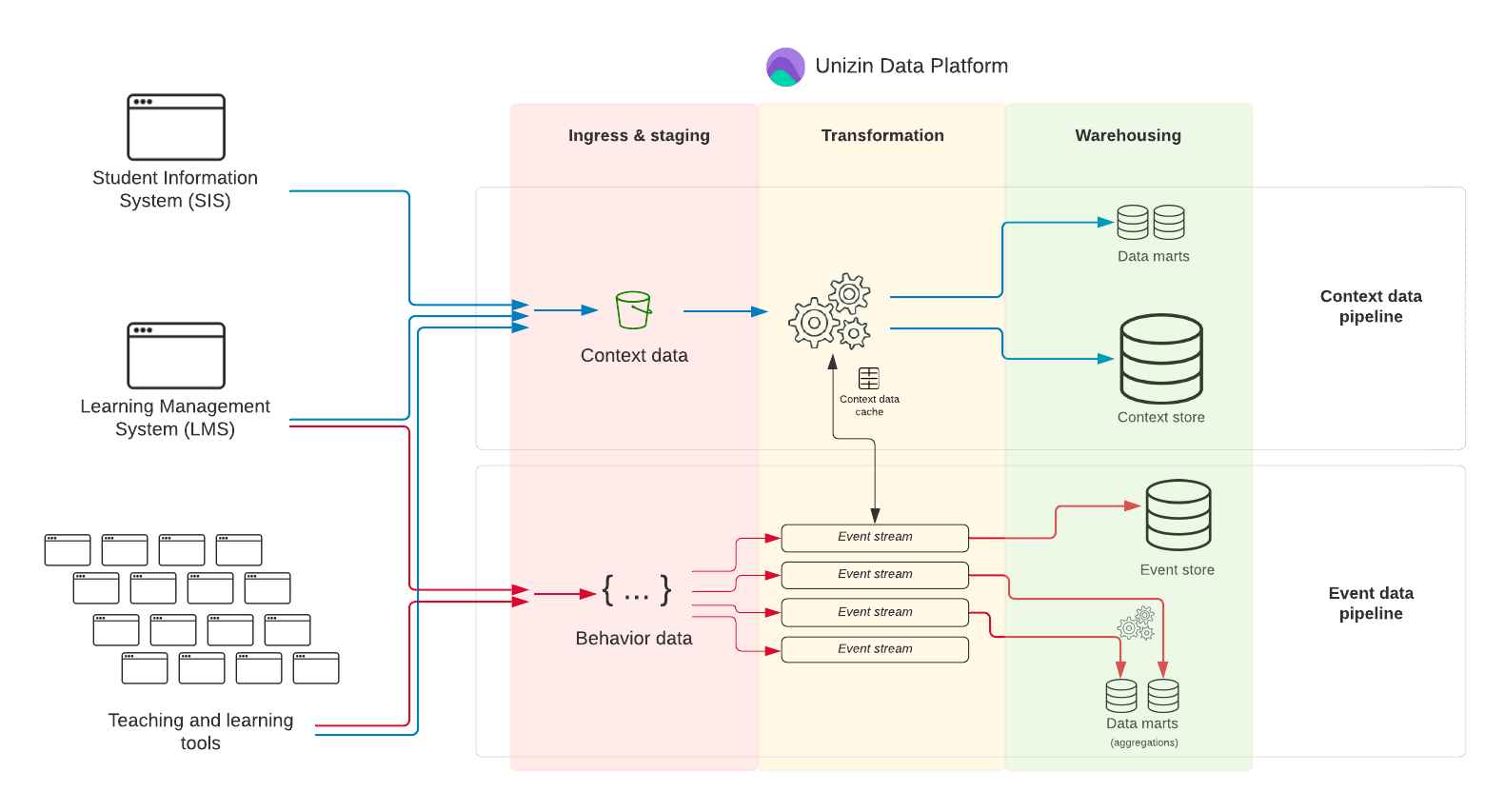
Fig 2: Source: https://resources.unizin.org/display/UDP/System+overview
The context data and the behavior data will be ingested into UDP and processed in different ways, resulting in two different data pipelines.
The behavior data will be ingested, sending Caliper events to a UDP endpoint that is listening for them. Then, the data is enriched using the context data, adding context information to the event. To do this, the system exporting the events needs to be Caliper-compatible.
The context data injection is slightly more complicated. Every night, UDP needs the complete extraction of all the content from the different systems. To ingest that content, it first needs to be converted to one of the available “loading schemas.” That is how UDP has to “standardize” and “unify” all the different possible data sources.
There is a loading schema for LMS data, a loading schema for SIS information, and some other loading schemas.
What is a loading schema? It is a set of CSV files that define the relations between entities and the data that UDP will store. We will talk more about these schemas later in this article, but the basic idea here is that the exported data from one’s LMS, or SIS, or educational tool needs to be converted to a bunch of CSV files with a specific format.
Once the data is converted, the files are placed in a bucket, and UDP ingests them. During the ingestion process, all the entities are mapped in some common tables that will be used later as join tables in the queries. In that way, a user in the LMS will be matched with the same person in the SIS. Of course, this process is not magic, and the information needs to be there. We will talk about it later.
From that moment, once the ingestion and processing are finished, the data can be queried using the Unizin Common Data Model (UCDM), and the answers will contain information about the different systems.
THE PROBLEMS TO SOLVE
As said, our task on this project was (among other things) to create a system that would automatically export the data from a D2L Brightspace LMS every night and inject it in UDP.
It is important to note that the Unizin Common Data Model (UCDM) is a product of institutional SIS representations, logical definitions of learners, and learning environments represented in the Common Educational Data Standard (CEDS) and Canvas data.
In this case, the LMS was different, and it was the first time that anyone was going to ingest data from a non-Canvas LMS in UDP, so one of the most complex tasks was to align the data in Brightspace with the LMS loading schema in the UDP, because this loading schema was modeled with a generic intention, but in some aspects is too similar to the Canvas schema.
Another problem we needed to solve was that every night, we would move and process all of a big university’s data from the last 5 years from an LMS. That implies processing many GBs of data, and we had an approximate window of two hours to finish the entire process.
Additionally, we wanted this system to be easily reusable in other projects with other LMSs or SISs.
THE INITIAL IDEA
To summarize, we had four things to do:
- Export the data from the LMS
- Insert it in a Relational Database (We will explain why a relational database is needed later.)
- Transform the data from the LMS into the LMS loading schema CSV files
- Drop the files in the UDP ingestion bucket.
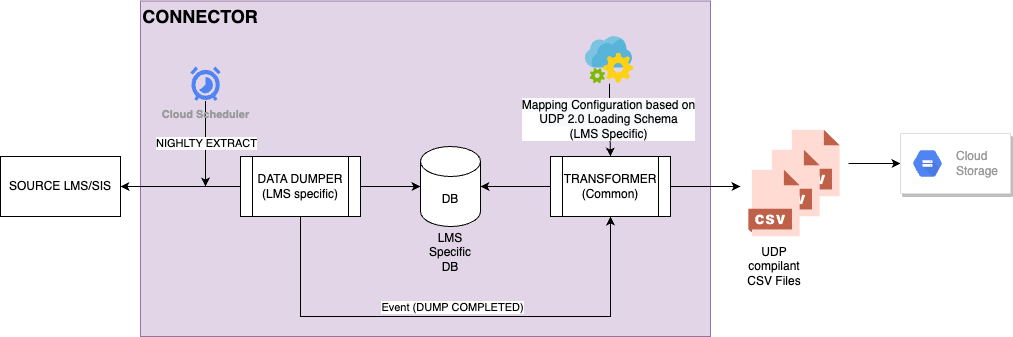
Fig 3: Generic diagram of the LMS Connector system
Let us explain the process in a little more detail.
Exporting the data:
D2L exports the data in several different files called DataSets, which is basically an export of the D2L database. It can be downloaded using an API; each file is a zip file containing a CSV file with data.
The D2L API provides a file with all the data until a specific date, as well as delta files with the differences for each day. After a week, a new complete file is created, and again, after that, each day a new delta file is added.
Unizin UDP needs the complete data every night. It does not accept deltas. Due to that, we needed to download the last full file and all the deltas after it to get the needed data.
To perform this task, as we like Java, we wrote a Spring Boot Java application that could perform this process of calling the APIs, downloading the files, and putting them in an intermediate temporal bucket. As the D2L files had very descriptive names about their nature (delta or full) and the dates they were created, it was simple to calculate the last full file and the delta needed to get all the data required.
Insert it in a Relational Database:
I am sure that many readers would be thinking at this moment: “Well, if you have your data in a bucket, why do you need to insert it in a database? Just create a data lake structure and query it!” That is undoubtedly a good question, and it could be a feasible solution.
We found that the transformation needed to convert the Brightspace data into the LMS loading schema was complicated. The queries to do that involved sometimes tens of tables, complex joins and transformations, and the best way to perform it was with some complex and heavy SQL queries. Sometimes, it was so complex that we decided a powerful relational database would perform much better than a data lake in this situation. At the same time, Brightspace data export was following a relational schema and was a perfect candidate to load in a Database.
So, once the export process ended, we created another process that inserted those files in the database. Sometimes, if it was a full file, the tables were deleted and recreated, and when it was a delta file, the data was merged with the current data.
To make this process more efficient and fast, we used a capacity from Postgres to load data directly reading from a file, and in that way, our application was not doing any heavy lifting, just launching the proper commands in the correct order.
Transform the data from the LMS into the LMS loading schema CSV files
This part of the process is where all the real magic happened. As mentioned, we wanted a generic system that could perform this transformation for different LMSs. To do that, we created a configuration file that contained all the instructions to create each of the LMS loading schema CSV files.
For each CSV file, this configuration file had the SQL query needed to get the data, the name and type of data for each column in the destination file, and some other information allowing the generic code to query the database and write the file correctly.
This will allow us to swap the configuration file with a different one to load the data from Blackboard, or Moodle, or any other system… or maybe another D2L Brightspace LMS from another university, as that would require some small changes in the SQL queries due to the possible different customizations that a school can have in the way they use the LMS.
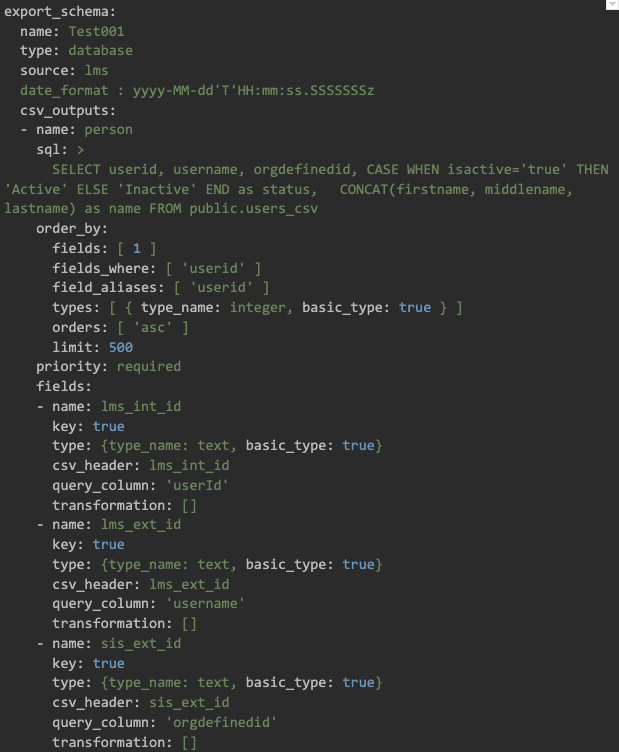
Fig 4: Fragment of the configuration file to generate the person.csv file.
Once the system that loads the data into the database is finished, the “transformer,” created with another Java Spring Boot application, will start the process, and reading the configuration file will query the database and create all the needed files.
Drop the files in the UDP ingestion bucket.
This was the easiest part; once we had all the files in a temporal bucket, we launched a process that moved them to the right bucket for the UDP process.
THE WALLS WE HIT
After dividing the process into its different phases, we needed to combine all the pieces and run the full process. As it turns out, this was more challenging than expected.
We had several implementations doing similar tasks built in Amazon Web Services (AWS) in the past. It was a simple architecture. We just need to containerize the Spring Boot application and launch it with AWS Fargate based on some triggers and deltas. AWS Fargate allows you to run a container until it decides to end. There is no time limitation, and the process can run for seconds or days, and as said, it can be triggered programmatically from a lambda or any other code.
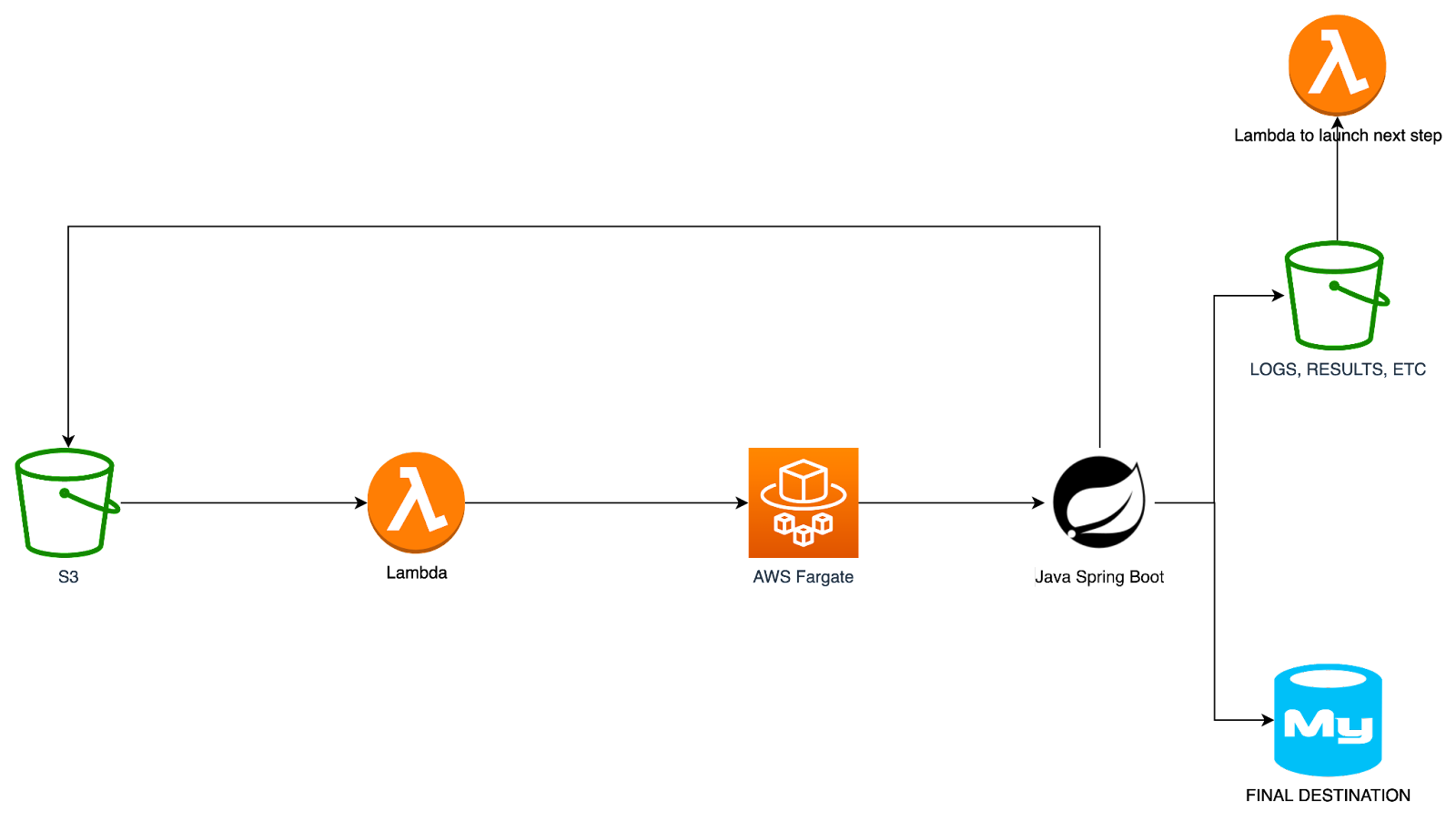
Fig 5: Simplified diagram to launch a Spring Boot
containerized app in AWS from a previous project.
But, UPD uses Google Cloud Platform (GCP), and Google was one of the partners on this project, so of course, it was a requirement to use GCP to implement this solution.
GCP is a great Cloud service provider, but it does not have a direct “translation” of everything that AWS has (and vice versa), and AWS Fargate is one of the services without a totally similar alternative. Due to that, we needed to find alternatives to our full S3-Lambda-AWS Fargate architecture.
GCP has several tools able to launch containers or run your java code. But, none of them were meeting our needs for this project:
- Cloud Run: This is what everyone suggests as the alternative to Fargate. However, it has two prominent incompatibilities with our purpose:
- There is a limit to the time of the task, and we are dealing with huge file processing that can take more than 1 hour. We tried breaking the tasks, and it almost worked, but it was very prone to errors and made the process too long. This was a deal breaker.
- It needs to be called by HTTP and will respond with HTTP. This is an inconvenience because we wanted to call it programmatically with a cloud function or trigger it from a PubSub queue.
- Google Kubernetes Engine: This allows you to launch any container, any time you want, programmatically as we wanted. But, again, some problems:
- To run a task that can take one hour or maybe two hours with a lot of processing happening, Kubernetes demands setting up some powerful servers working 24 hours. We would be paying for 24 hours/day usage of a system that we would only use 2 hours a day. It was overkill and very costly. As we say in Spain, it was like “killing flies with a cannon.” (Spoiler… we needed to return to this at the end in an indirect way).
- Managing and configuring a Kubernetes system is not trivial.
- Cloud Build: Using some dirty tricks, Cloud Build can build and run a container for testing purposes during the build, and we could use this to launch our container.
- But, it was too artificial and after some tests, we found a large number of other issues with it. Not an elegant solution at all.
- App Engine: A nice option to run Java code, but:
- It is too related to running web apps, and is not sufficiently equipped to handle a backend process launched by an event that starts and ends.
- Google Compute Engine: Launching programmatically a GCE resource to run the process, and stopping it when finished was another option, maybe even the most promising one. We played with the idea and ran some tests, and it looked encouraging, but:
- It added a lot of overhead code just to maintain the costs, delete old resources, and clean everything in a failure scenario. Overcomplicated.
- Dbt: Dbt is a tool that allows the use of SQL queries and transformations used on other projects at Unicon to perform some similar tasks
- However, it is not a native GCP tool, and Google was our customer. We needed to find something using GCP functionality.
After all these unsuccessful tests, we decided to try not “doing the same as we did on AWS,” and we tried to divide the tasks into batches, use Cloud Functions, and change Spring Boot for just Java.
Cloud Functions have a time limit, so we decided to process a limited amount of rows from the file each time and two minutes before arriving at the time limit, then stop and launch another cloud function that will continue with the process. It worked, but again, it was very prone to errors and added a lot of overhead to control the process. We looked at it, and no one liked it (including me). We kept it as an alternative in case we could not find another solution, but we wanted to avoid it if possible.
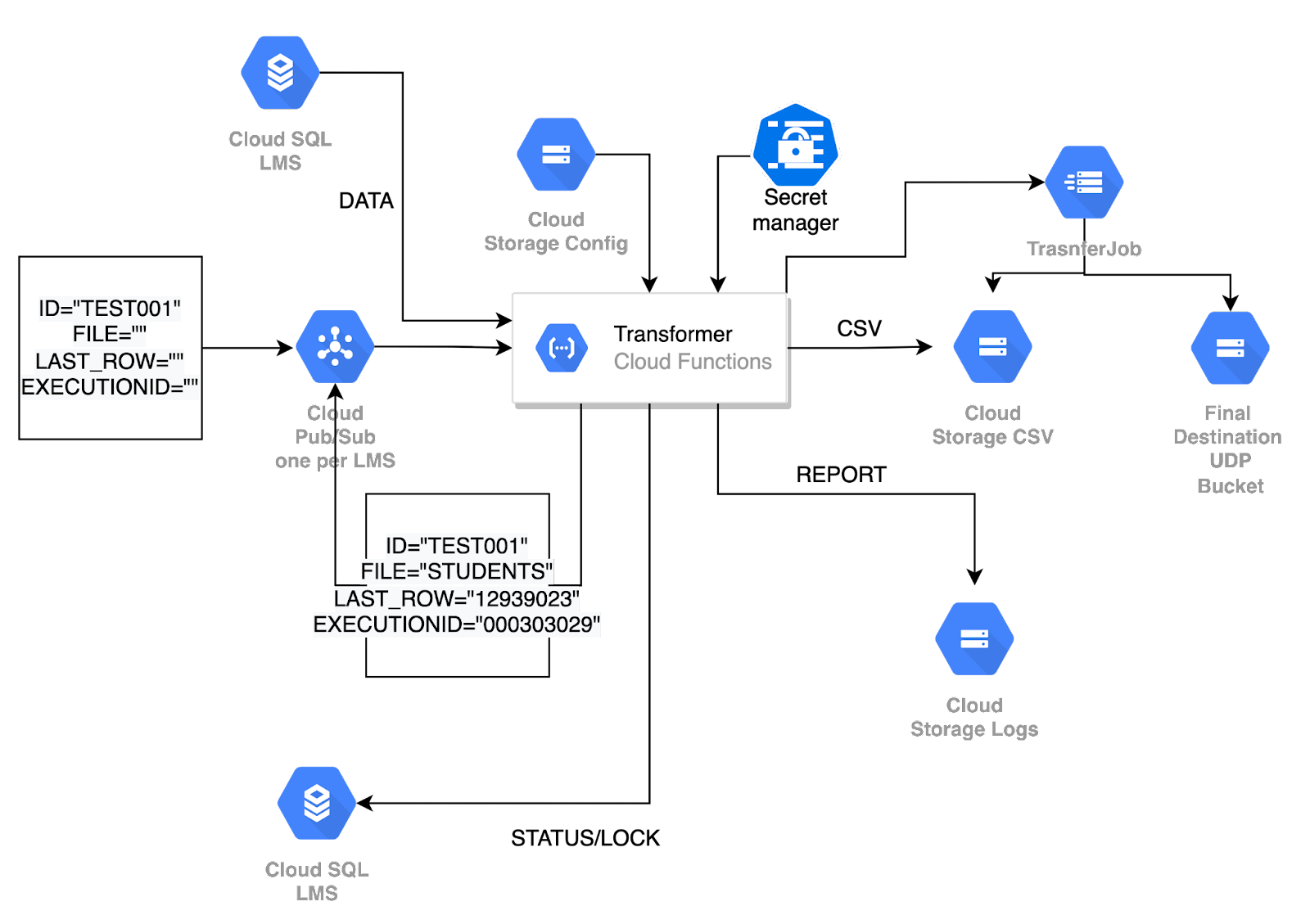
Fig 6: Diagram of the Cloud Function solution for the transformer
that self-launches until the process is finished.
We refreshed our training on GCP, and I prepared myself for the GCP Certification Data Engineering exam. During the training, I looked through all the Data tools that GCP was offering to try to find a solution that fit our problem.
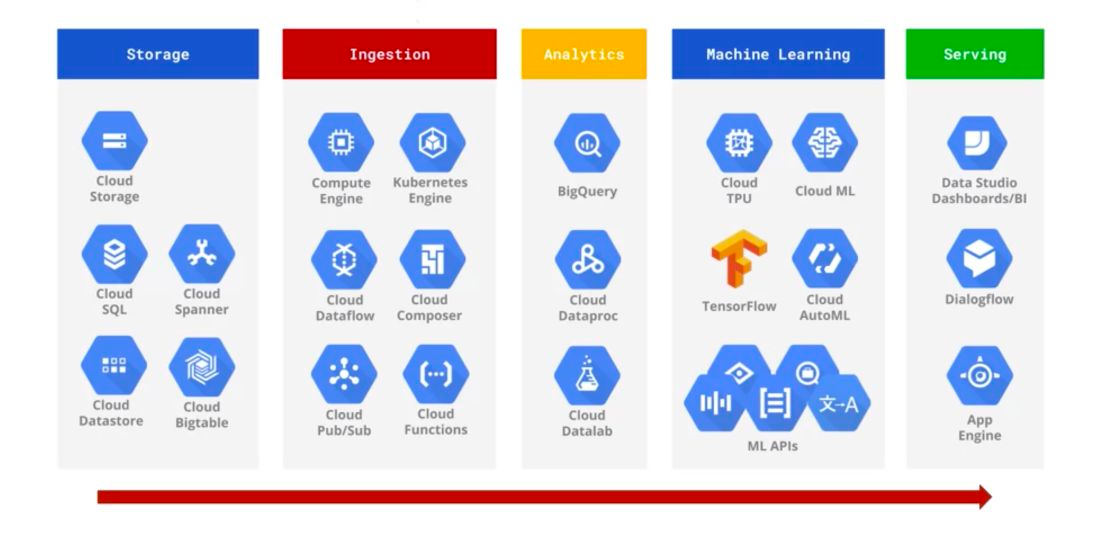
Fig 7: GCP Data related solutions
THE FINAL SOLUTION
And then we found that the best approach to this problem was always in front of our eyes. UDP uses Apache Airflow (https://airflow.apache.org/) to manage all the complex tasks that happen during the data ingestion, processing, and storage. We used the airflow logs and UX interface to control the ingestion problems.
During my exam preparation, I learned about a service called Google Cloud Composer, which is a Google-managed Apache Airflow service.
Cloud Composer (aka Apache Airflow) is a tool that defines a graph of tasks that will happen one after the other based on conditions and requirements. It has many options to launch the tasks (called operators). These are the four most common:
- BigQuery Operator: Query tables, export data, etc.
- Kubernetes Pod Operator: Execute tasks on a Kubernetes pod.
- Bash Operator: Execute bash commands.
- Python Operator: Execute Python functions.
The Kubernetes Pod Operator allows us to launch containers, wait for them to finish, and launch more after in a controlled flow.
Didn’t we say we did not want to use Kubernetes, because it was complicated and expensive? Yes, we said that, but… Cloud Composer can manage it for us, launch it, and destroy it after finishing the tasks.
So, finally, we can have our Kubernetes cluster just working for the time we need it!
However, at this point in this article, we all know there is a “but” after every excellent tool we try. The “but” is that Cloud Composer runs 24 hours on its own Kubernetes cluster. So, to avoid having a Kubernetes cluster 24 hours running, we need to run a Kubernetes cluster 24 hours!
Sounds crazy, but it makes sense, because the size and power of the Cloud Composer Kubernetes cluster can be small (so cheaper) because it just controls the tasks, and the size of the one we launch to deal with the tasks can be bigger (more expensive) and be on for a few hours. This, as a complete solution, is cheaper than having the expensive one running for 24 hours.
SOME DETAILS ABOUT THE SOLUTION
Cloud composer uses what it calls “DAGs.” Each DAG describes tasks that can be performed one after the other, in parallel, or in any way we can imagine and program.
For our solution, we wrote 3 DAGs:
- Downloader - To download all the files from D2L to the bucket
- Extractor - To read the files from the bucket and insert the information in the database
- Transformer - To query the database and generate the CSV files that UDP needs.
Each Dag was divided into smaller tasks (usually one per file in the Extractor and Transformer) that allowed us to launch some in parallel, saving some time. To do this, we created three container images that were launched on each of the dags, as said, for each individual file.
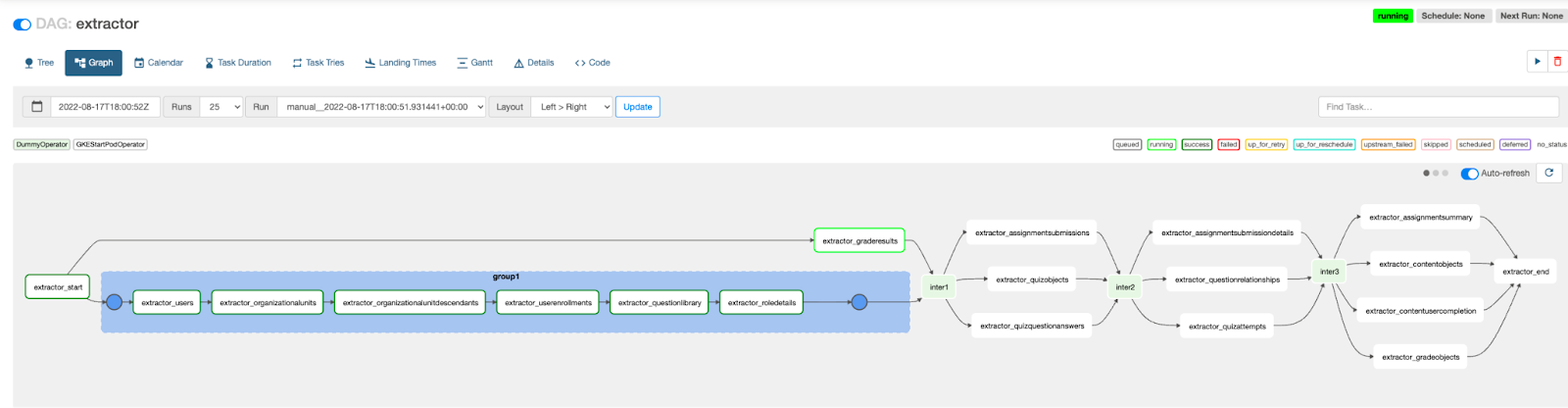
Fig 8: Extractor DAG
Once we had all this in place, we launched it, and we found that everything was moving very slowly, taking up to 12 hours to complete. We dedicated our efforts at this point to improve the performance, focusing on these tasks:
- Tuning the complex SQL queries to be the most efficient possible.
- Creating the proper indexes in the database to accelerate performance.
- Organizing the DAGs in parallel tasks in blocks where the complex and heavy SQL queries were not locking each other. Waiting for other SQLs that were using the same tables was the main bottleneck.
With all this tuning, processing the full LMS data from start to end went from 12 hours to something around 2 hours, an amount of time that was inside the original margins in the requirements.
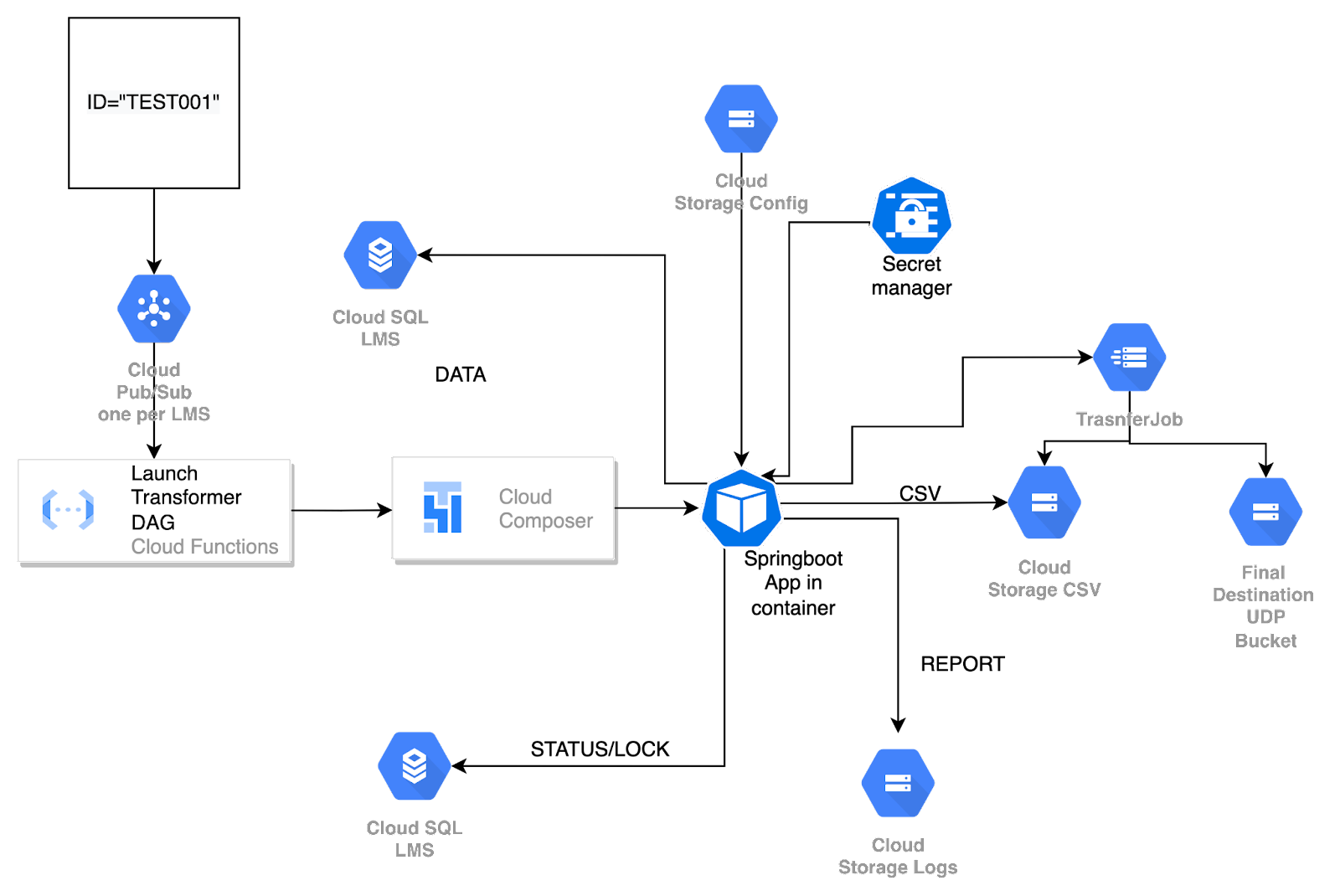
Fig 9: Individual diagram for the transformer DAG
Once all the files were generated, they were moved simultaneously to the UDP bucket using the Google TransferJob utility, and were waiting there for UDP to launch the loading process.
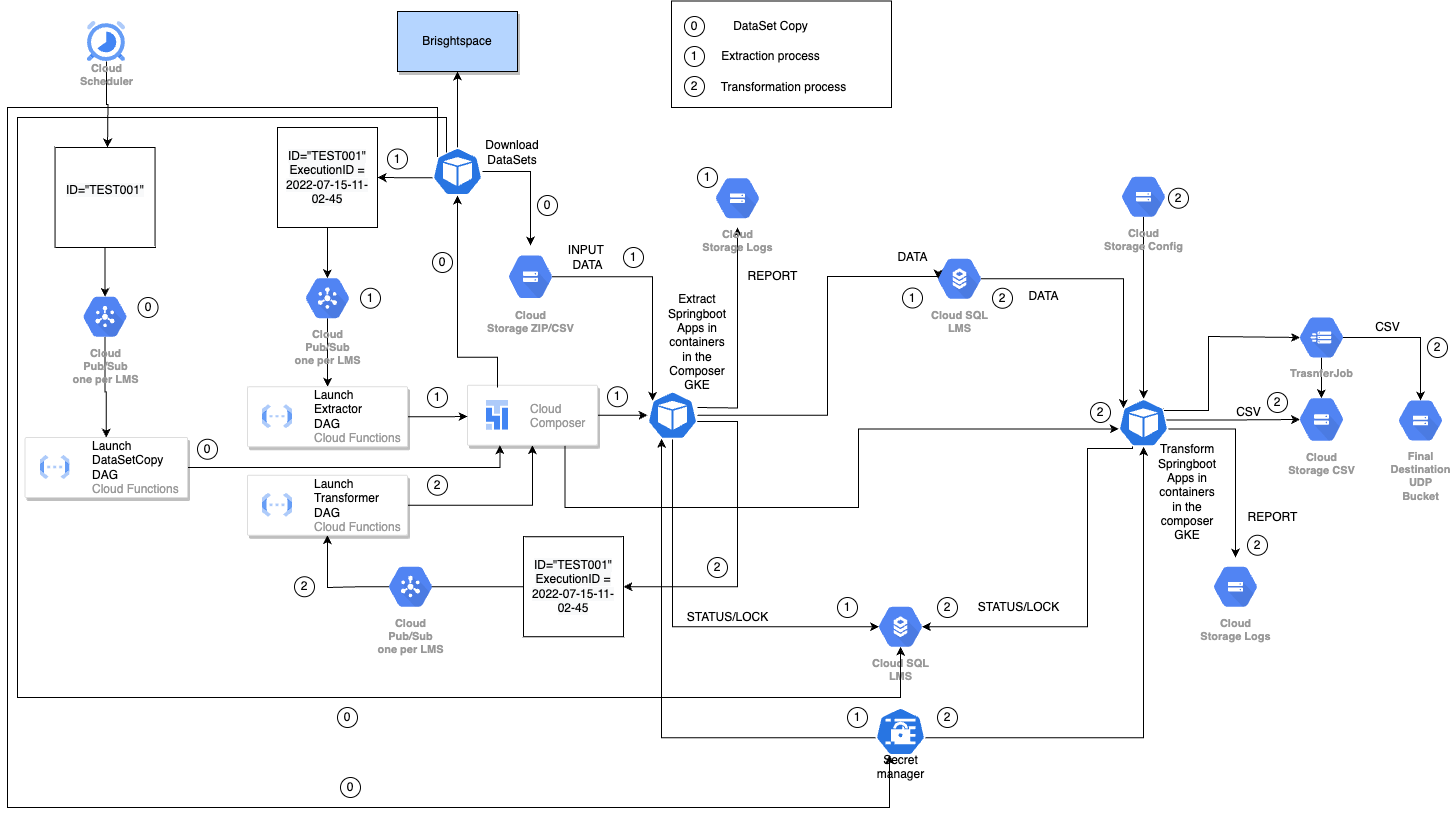
Fig 10: Full diagram of the complete process.
It must be noted that this was just the technical part of moving the data, but one of the project’s most complex pieces was figuring out how to convert the D2L Brightspace data to the Unizin LMS loading schema. During that process, we had a lot of conversations with D2L, our customer, and Unizin that helped them to evolve the loading schema and the way that they were loading the data, to make this process more generic and not just “Canvas-centered.” This will make it much easier to ingest data from other LMSs in the future.
LAST COMMENTS
With a solution like the Unizin UDP, an institution can relate all the separated content from LMS and SIS, allowing it to analyze the data as a whole and in a known data schema.
Feeding the system is a complex process, and there are multiple approaches to doing it. Each scenario will have different requirements, so the final architecture can be completely different.
This project provided us with much knowledge of different GCP technologies. It is essential to realize that GCP and AWS (and AZURE) are not always directly interchangeable. Most of the services in one cloud provider have a similar service on the other, but not all of them do and when they do, they are not always totally equivalent. Trying to translate “literally” what you are used to doing in one of those systems to another can be a mistake, and it is better to learn how a similar problem can be solved, maybe with different tools, on each platform.
Thinking outside of the box and being open to modifying some requirements in order to find a better solution is always good advice. Adaptation and flexibility usually save time, money, and headaches.
If you want to know more details about this project or line of work, we at Unicon will be happy to help you. If you are interested in knowing more about the UDP, please reach out to info@unizin.org.



